
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
- 엘라스틱서치
- kubernetes
- 자바스크립트
- 오블완
- Effective Java 3
- java
- ElasticSearch
- effectivejava
- Effective Java
- 스프링
- 스프링핵심원리
- 스프링 핵심원리
- 예제로 배우는 스프링 입문
- Sort
- 자바
- 이펙티브 자바
- 스프링부트
- 이차전지관련주
- 카카오
- 코딩테스트
- 김영한
- k8s
- Spring
- 카카오 면접
- 클린아키텍처
- 알고리즘
- 알고리즘정렬
- 이펙티브자바
- 티스토리챌린지
- JavaScript
- Today
- Total
Kim-Baek 개발자 이야기
클린 아키텍처 - 5장 객체 지향 프로그래밍 본문
객체지향이란 무엇일까? 면접에서 자주 물어보는 질문이기도 하다. "데이터와 함수의 조합" 이라고 말하는 사람도 있고, "실제 세계를 모델링하는 새로운 방법"이라고 대답하는 사람도 있다고 한다.
하지만 두 개 모두 만족스러운 답변이라고는 하지 않는다. 캡슐화, 상속, 다형성을 통해서 설명하는 사람들도 있는데 그렇다면 이 세 가지 개념이 어떤 것인지 한번 살펴보도록 하자.
캡슐화
데이터를 응집력 있게 구성하고, 구분선 바깥에 데이터는 숨겨지고, 일부함수만 외부에 노출되는 것을 말한다. 객체 지향 언어에서는 private, public 등을 통해서 이를 표현한다. 하지만 객체 지향에서만 해당 개념이 있는 것이 아니다.

c언어에서의 사용하는 방법인데, point.c로 구현을 하고, point.h 파일로 해당 기능에 대한 선언을 한다. 사용자는 point.h 를 가져가서 사용하게 되는데, 그러면 point 의 내부구조가 어떻게 구성이 되어있는지는 알 수가 없다.
distance 함수를 호출해서 값을 얻을 수 있지만, 어떤식으로 동작하는 지는 모르는 것이다. 이것도 완벽한 캡슐화이다.

C++에서는 어떤식으로 캡슐화를 이용하는 지 살펴보자. C++ 컴파일러는 클래스의 인스터스 크기를 알아야하는 기술적인 이유 때문에, 헤더 파일에 멤버변수를 선언해야한다.
private 이라는 키워드로 이 변수에 접근하려는 시도를 컴파일러가 막겠지만, 이것은 컴파일러의 기술적인 이슈를 해결하기 위한 임시방편이다. 객체 지향 프로그래밍이 강력한 캡슐화가 맞을까? 오히려 C언어에서 누렸던 완벽한 캡슐화를 약화시킨 것이다.
public class Point {
private double x;
private double y;
public Point(double x, double y){
this.x = x;
this.y = y;
}
public double distance(Point point){
double dx = point.x - this.x;
double dy = point.y - this.y;
return Math.sqrt(dx*dx + dy*dy);
}
}자바는 헤더파일이 따로 없고, 이렇게 클래스로 구성될 것이다. C++과 큰 차이가 없다는 것을 볼 수 있다.
상속
상속은 단순히 어떤 변수와 함수를 하나의 유효 범위로 묶어서 재정의하는 것이다. 객체 지향 언어가 나오기 전에 상속은 불가능했을까? C언어에서 상속을 사용하던 방식을 한번 보자.


distance 함수에 NamePoint 구조체를 넣어서 값을 구하는 것을 볼 수 있다. 이전으로 돌아가 distance 구조체를 다시한번 살펴보자.
double distance (struct Point *p1, struct Point *p2 );
NamePoint 가 아닌, Point 구조체를 파라미터로 받는데, 어떻게 이것이 동작할까? 이것은 NamePoint 가 Point 를 포함하는 상위 집합으로 Point 에 대응하는 멤버 변수의 순서가 그대로 유지되기 때문이다.
이런식으로 상속을 구현하는데, 사실 객체 지향의 상속 만큼 편리하다고는 생각할 수 없다. 순서를 정확하게 맞춰야 하고, 업캐스팅도 매번 해줘야 하는데 상속이라는 개념을 사용을 한다 정도로 볼 수 있을 것 같다.
다형성
객체 지향 언어 이전에 다형성은 존재했는지도 마찬가지로 살펴보자.
#include <stdio.h>
void copy() {
int c;
while ((c=getchar()) != EOF )
putchar(c);
}위 코드는 getcha 함수로 문자를 읽고, putchar 함수로 문자를 쓰는 간단한 복사 프로그램이다. 두 함수는 STDIN, STDOUT 에서 사용되는 데, 이 두개는 어떤 장치에 입출력을 하는 것일까? 써본 사람은 대부분 알겠지만 콘솔용 입출력 드라이버다. ( 키보드 모니터 )
UNIX 운영체제는 모든 입출력 장치 드라이버가 아래와 같은 5가지의 표준함수를 제공할 것을 요구한다.

FILE 이라는 구조로 표준함수를 관리하는데, 외부 입출력 장치를 모두 동일하게 파일처림 읽고 쓰고 할 수 있게 하겠다는 것을 알 수 있다.

STDIO 같은 콘솔용 입출력 드라이버는 이 함수를 다시 가져와서 자신들의 입출력에 맞게 정의를 한다.

이렇게 해서 STDIN을 FILE* 로 선언하면, 내부에 있는 5가지 함수를 사용하는데, 이는 실제 입출력에 맞는 구현이 되는 것이다. getchar 메소드의 경우 STDIN 으로 참조되는 FILE 구조의 read 포인가 가리키는 함수를 호출하는 것이다.
이렇게 함수를 가리키는 포인터를 응용한 것이 다형성으로 사용이 된 것이다. 하지만 함수 포인터는 안전하지 않고 위험하다. 포인터를 초기화 한다던가, 포인터를 통해 모든 함수를 호출하는 관례를 지켜야 한다.
객체 지향 언어는 이런 관례를 없애서 실수할 위험을 줄여준다. 직접적으로 제어하던 흐름을 객체 지향에서는 제어흐름을 간접적으로 전환하는 규칙으로 만들었다.
이런 다형성을 통해서, 새로운 입출력 장치가 추가될 때 어떤 장점이 있는지를 생각해보자. 새로운 입출력 드라이버가 FILE에 정의된 표준 함수를 구현한다면 복사 프로그램은 전혀 변경될 것이 없다. 장치에 의존적이지 않은 장치 독립적이고, 뺐다 갈아끼웠다 할 수 있는 플러그인 아키텍쳐인 것이다.
의존성 역전
다형성을 안전하고 편리하게 적용하기 전 소프트웨어의 메커니즘을 보자.
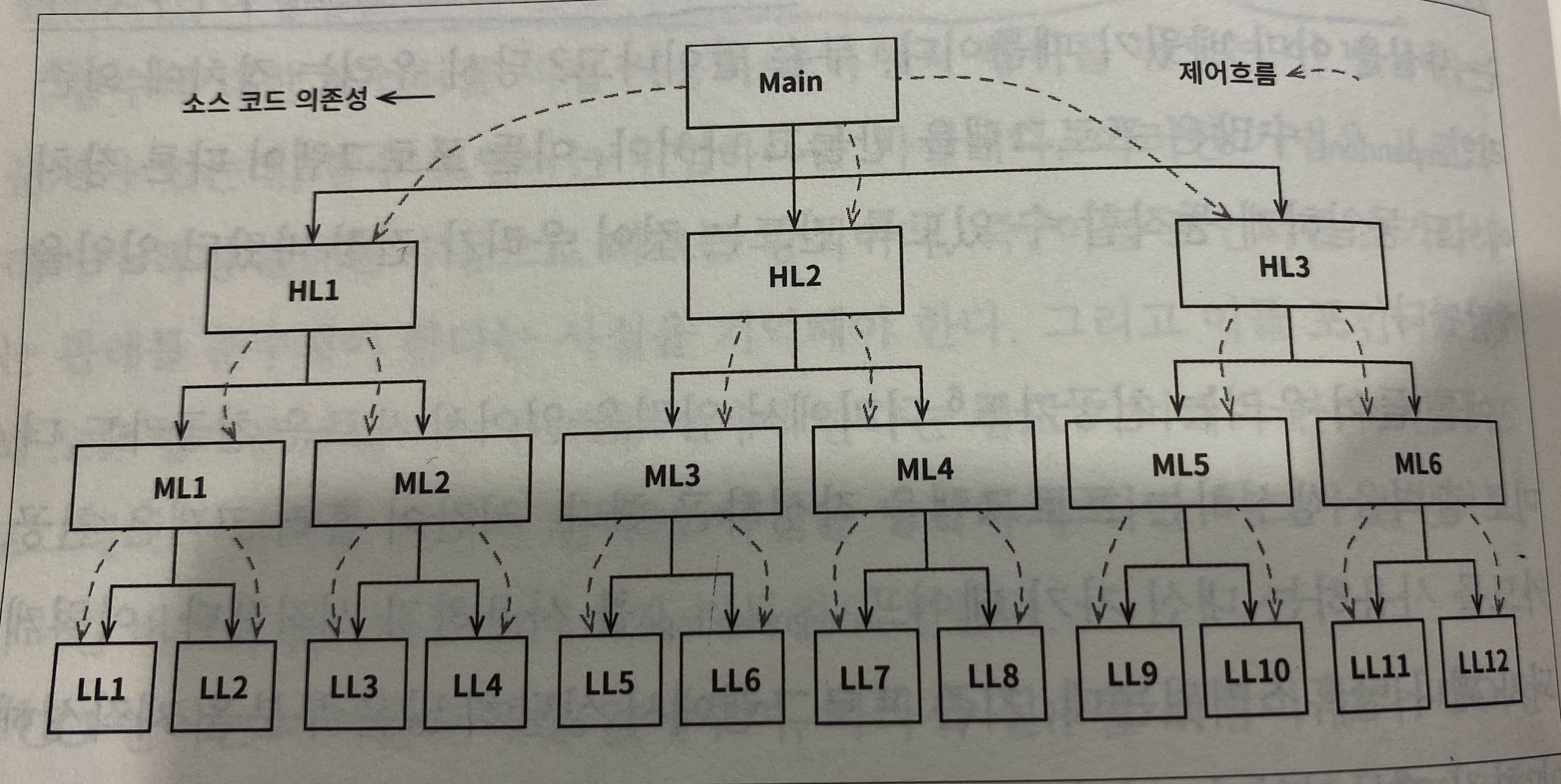
main 함수부터 시작을 하고, 상위 레벨의 모듈을 호출하기 위해서는 해당 모듈 함수의 이름을 지정해야 한다. 아까 본 c언어에서는 #inlcude 로 할 수 있다. 이렇게 하위 레벌의 모듈를 호출하기 위해서 피호출 함수가 포함된 모듈을 명시적으로 지정해줘야 한다.
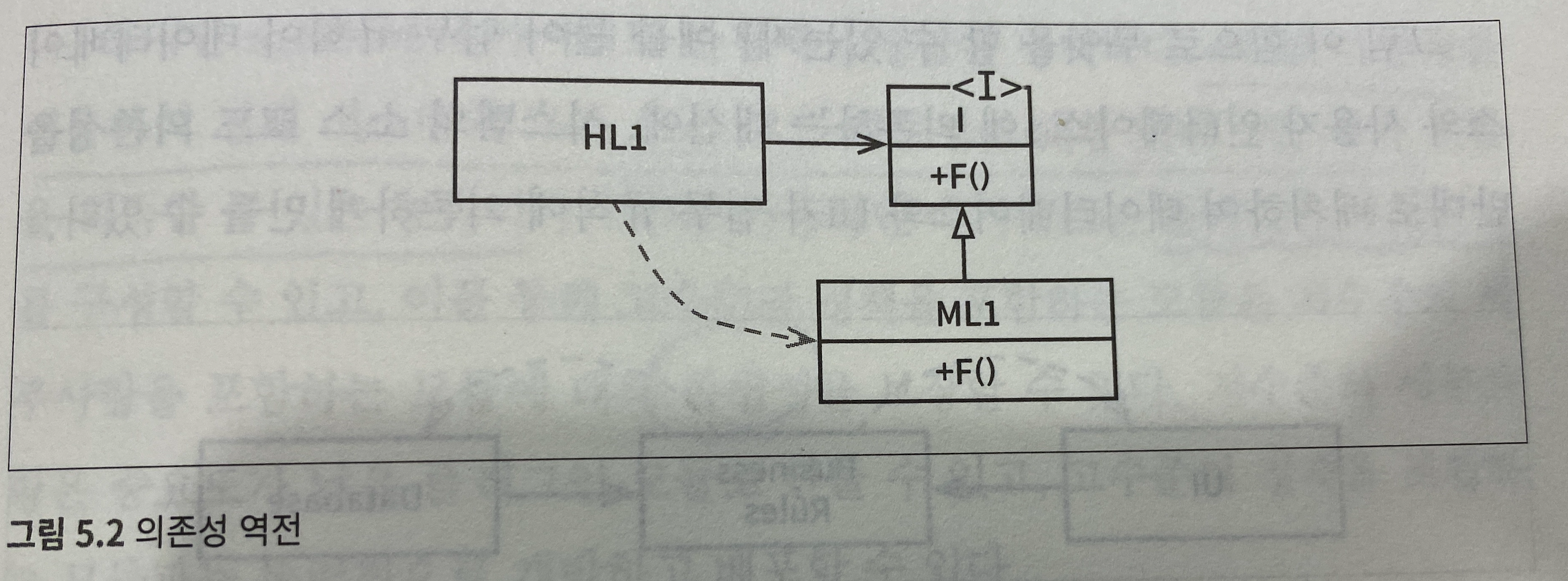
HL1 모듈은 ML1 모듈의 F() 함수를 호출하고 있다. 하지만 소스코드에서는 인터페이스는 I 를 통해서 F() 함수를 호출한다. 하지만 이 인터페이스는 런타임에는 존재하지 않는 것이다. HL1은 그냥 ML1의 F() 함수를 호출하는 것이다
그러나 소스코드의 의존성은 정반대인 것을 알 수 있다. ML1은 인터페이스인 I를 상속받고, I를 통해서 F() 라는 함수를 정의하고 사용하는 것입니다. 이렇게 제어의 흐름과는 반대로 의존성이 나타나는 것을 의존성 역전이라고 합니다.

의존성이 역전을 예시를 들어서 보변, 업무 규칙이 UI와 Database에 의존을 했다 ( 코드를 알고, 직접 관리&사용했다 )고 생각을 해봅시다. 그러면 UI의 소스가 비뀌면 업무 규칙 내에서도 같이 변경을 해줘야하는 일이 생겼습니다.
하지만 아까 본 것처럼 의존성을 역전하게 되면, UI와 Database 는 플러그인 처럼 사용이 된다는 것 입니다. 소스 코드의 변경이 되더라도 업무 규칙을 알 필요도 없고, 정해진 룰 대로 사용만 하면 되는 것 입니다.
이렇게 되면 업무규칙과 UI, Database는 독립적으로 배포할 수 있게 됩니다. 배포 독립성을 같게 되는 것이고, 각 모듈을 독립해서 개발할 수 있게 되는 것이니 개발 독립성도 갖게 되는 것입니다.
결국 객체 지향이란 다형성을 이용하여 전체 시스템의 모든 소스 코드 의존성에 대한 절대적인 제어 권한을 획득할 수 있는 능력이라고 할 수 있습니다. ( 플러그인 아키텍처, 독립성을 보장! )
'개발' 카테고리의 다른 글
| 클린 아키텍처 - 6장 함수형 프로그래밍 (1) | 2022.02.02 |
|---|---|
| 클린 아키텍처 - 4장 구조적 프로그래밍 (0) | 2022.02.02 |
| 클린 아키텍처 - 3장 패러다임 개요 (0) | 2022.02.01 |
| 클린 아키텍처 - 2장 두 가지 가치에 대한 이야기 (0) | 2022.01.31 |
| 클린아키텍처 - 1장 설계와 아키텍처란 (0) | 2022.01.31 |


