
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- JavaScript
- 카카오
- 자바
- ElasticSearch
- 오블완
- 이펙티브자바
- java
- 스프링핵심원리
- Sort
- 스프링 핵심원리
- 스프링부트
- 클린아키텍처
- effectivejava
- Spring
- Effective Java 3
- k8s
- 알고리즘
- 스프링
- 알고리즘정렬
- 카카오 면접
- 예제로 배우는 스프링 입문
- 코딩테스트
- 엘라스틱서치
- kubernetes
- 티스토리챌린지
- 이펙티브 자바
- 김영한
- Effective Java
- 이차전지관련주
- 자바스크립트
- Today
- Total
목록컴퓨터 공학/자료구조, 알고리즘 (11)
Kim-Baek 개발자 이야기
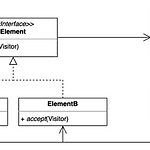 디자인패턴 - 비지터 패턴
디자인패턴 - 비지터 패턴
디자인 패턴 중, 비지터 패턴에 대해서 강의를 듣고 정리해보았다. 위의 다이어그램이 비지터 패턴의 다이어그램이다. 중요한 것은 Element( 자료구조 ) 는 변화하지 않는다는 것과 vistor ( 서비스 로직 ) 가 추가되는 기능을 가진다는 것이다. 비지터 패턴은 일반적으로 프로그래밍을 하는 과정에서 생각하는 것과는 약간 다른데, 아래와 같다고 보면 된다. 일반적 : 방문자는 “구매” 라는 기능을 가지고 가게에 간다. 버거킹에 가면 “햄버거”를 사고, 피자헛에 가면 “피자"를 산다. 비지터패턴 : 가게에 방문자가 들어간다. 가게가 방문자에게 자신의 정보를 주고, 방문자는 정보에 따라 “버거킹의 햄버거 구매”, “피자헛의 피자 구매” 라는 기능을 호출한다. 코드 예시를 통해서 살펴보도록 하자. 비지터 패..



Heap Sort는 Heap 이라는 자료구조를 이용해 정렬을 하는 알고리즘이다. Heap 이란 완전 이진 트리 형태로 Paren Node 는 Child Node 보다 반드시 큰(작은) 값을 가진다. Heap Sort의 경우 항상 O( N log(N) ) 의 시간복잡도를 가진다. 우선 모든 원소를 최대(최소) Heap에 삽입한다.( O(logN) ) Heap 트리의 최대(최소) 값을 출력한다.( O(1) ) 최대(최소) 값을 제거하고 Heap을 재배열 한다.( O(logN) ) Heap이 빌때가지 반복한다.( O(N) ) Stable 을 만족하지 않는다. #include #include #include using namespace std; int main() { vector v = { 3,1,4,1,5,9..
Quick Sort는 데이터내의 Pivot 값을 정하고 그 기준으로 두 개의 부분집합으로 나눈다. 한쪽은 Pivot보다 작은 값을 다른 한쪽은 Pivot보다 큰 값으로 나눈다. 더 이상 쪼갤 부분집합이 없을 때까지 재귀적으로 진행한다. Quick Sort는 어떤 Pivot 값을 고르는지에 따라 성능이 결정된다. 가장 이상적인 Pivot은 전체 데이터를 절반씩 쪼갤 수 있어야 한다. 이 경우 O(N log(n)) 의 복잡도를 가진다. 최악으 경우는 집합의 최소(최대) 값을 Pivot으로 고른 경우이다. 그러면 한쪽의 부분집합은 비어있고, 다른 한쪽은 n-1개의 원소가 있다(pivot 제외). 이 경우 재귀호출 횟수가 O(N)이며, 최악의 경우 O(N^2) 의 복잡도를 가진다. 하지만 평균적으로 O(N lo..
Merge Sort는 Divide and Conquer 알고리즘 기법이다. Merge Sort의 경우 항상 O( N log(N) ) 의 시간복잡도를 가진다. 성능은 전반적으로 Quick Sort 에 비해 떨어진다. Stable 하다 추가 메모리 공간(Not in-place)이 필요하다. C++의 stable_sort 가 Merger Sort 로 구현되어 있다. #include using namespace std; void merge_sort(int ary[], int left, int right); void merge(int ary[], int left, int mid, int right); int* temp; int main() { int ary[] = { 6,4,2,7,9,7,6,4,4,1,0 }; ..
Insertion Sort는 단순한 정렬 알고리즘 중 하나이다. 한번의 한 원소씩 이미 정렬된 다른 원소들과 비교하여 올바른 위치에 삽입하는 정렬이다. 삽입 정렬은 이미 정렬되어 있을때 O(N) 의 효율이다.(Best Case) Average, Worse Case의 경우 O(N^2) 이다. Bubble Sort에서 발전된 형태이다.(비교 횟수를 줄였다) 소량의 데이터를 처리할때 좋다. Stable 하다 무작위로 정렬된 많은 데이터의 효율이 매우 안좋다. #include using namespace std; void insertion_sort(int data[], int size); int main() { int data[] = {3,7,9,4,5,1,3,4,6,9}; insertion_sort(data,..
알고리즘 문제에서 정렬(Sort)는 중요한 기술이다. 여러가지 정렬 알고리즘이 있지만 기본적인 것 부터 하나하나 알아보자. 선택 정렬 (Selection Sort) 단순한 정렬 알고리즘 중 하나이다. 배열의 첫 번째 원소에서 시작하여 배열 전체를 훓으면서 작은(큰) 값을 찾아 첫 번째 원소와 바꿔준다. 이 작업을 (배열의 길이 - 1 ) 만큼 진행한다. 선택 정렬은 Best, Average, Worst Case 모두 O(N^2) 의 효율이다 - 원소를 바꾸는 횟수가 최대 n -1 이다. 즉 원소를 바꾸는 과정에서 많은 비용이 드는 경우에 효율적일 수 있다. - 선택 정렬은 다른 알고리즘에 비해 효율(performance) 가 좋지 않다. - stable을 만족하지 않는다. #include using na..
BFS는 너비우선탐색 이라고 블리는 Graph 알고리즘 중 하나이다. - BFS 는 일반적으로 Queue를 이용해 구현 - 시작 정점과 인접한 모든 정점을 방문하는 방법 - 얻어진 해가 최단 경로가 된다는 것을 보장 - 경로가 매우 길 경우에는 많은 저장 Memory 가 필요 C++를 이용해 BFS를 구현 #include #include #include using namespace std; vector* vertex; bool* checked; void bfs(int st); int main() { int n, m, s; int from, to; cin >> n >> m >> s; vertex = new vector[n + 1]; checked = new bool[n + 1]; for (int i = 0..
Tree Traversal Tree Traversal 은 트리 순회이다. Tree 자료구조에서 각각의 노드를 정화히 한 번만, 체계적으로 방문하는 과정이다. 전위 순회(PreOrder Traversl) Root 노드부터 탐색하기 시작한다. root => sub left => sub right PreOrder Traversal은 가장 깊은 왼쪽 노드부터 탐색하기 때문에, 우리가 잘 알고 있는 DFS 라고 생각하면 된다. def preOrder(node): print(node, end = ' ') if node.left != null: preOrder(node.left) if node.right != null: preOrder(node.right) 중위 순회(InOrder Traversal) 왼쪽 서브 트리..